...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
...
how we define when something is fit to be pulled* from one step in the workflow to the next
*Kanban is a PULL model, whereas Scrum is a PUSH model. This means tickets should only transition between steps in the workflow at the point that team members are going to work on them in the new step, not pushed to the next step in the workflow when a team member has finished with them in the previous step. eg. a ticket is moved from PR to Verifying in Stage when a team member has approved and merged the PR and the verifier is ready to start Verifying in Stage;
how we respond as a team to common day-to-day scenarios.
In Kanban, the tool for achieving this is to define ‘policies’ as reference points for both the above. These are designed to be organic (like the Definition of Done that we’re already familiar with).
Following the team workshop around these policies, I’ve set them out here as a draft for you all to review, comment on/modify.
...
Policy
...
Description
...
Backlog
What is the Backlog?
Who populates the Backlog?
Should the Backlog be ordered?
What should be the size of the Backlog?
What goes into the Backlog?
A record of conversations (ideally a 3 amigos ones) about things to be worked on in the next 3-6 iterations.
Anyone, as a result of having the conversation. Remember a Jira ticket is the result of the 3 Cs process - card, conversation, confirmation
Everything should be ordered - product-development and tech improvement tickets. As a team we need to align these two sides of the backlog wherever possible (Refinement meetings, Planning ones and Stand ups - up to 30% of what we work on in any iteration should be Tech Improvement).
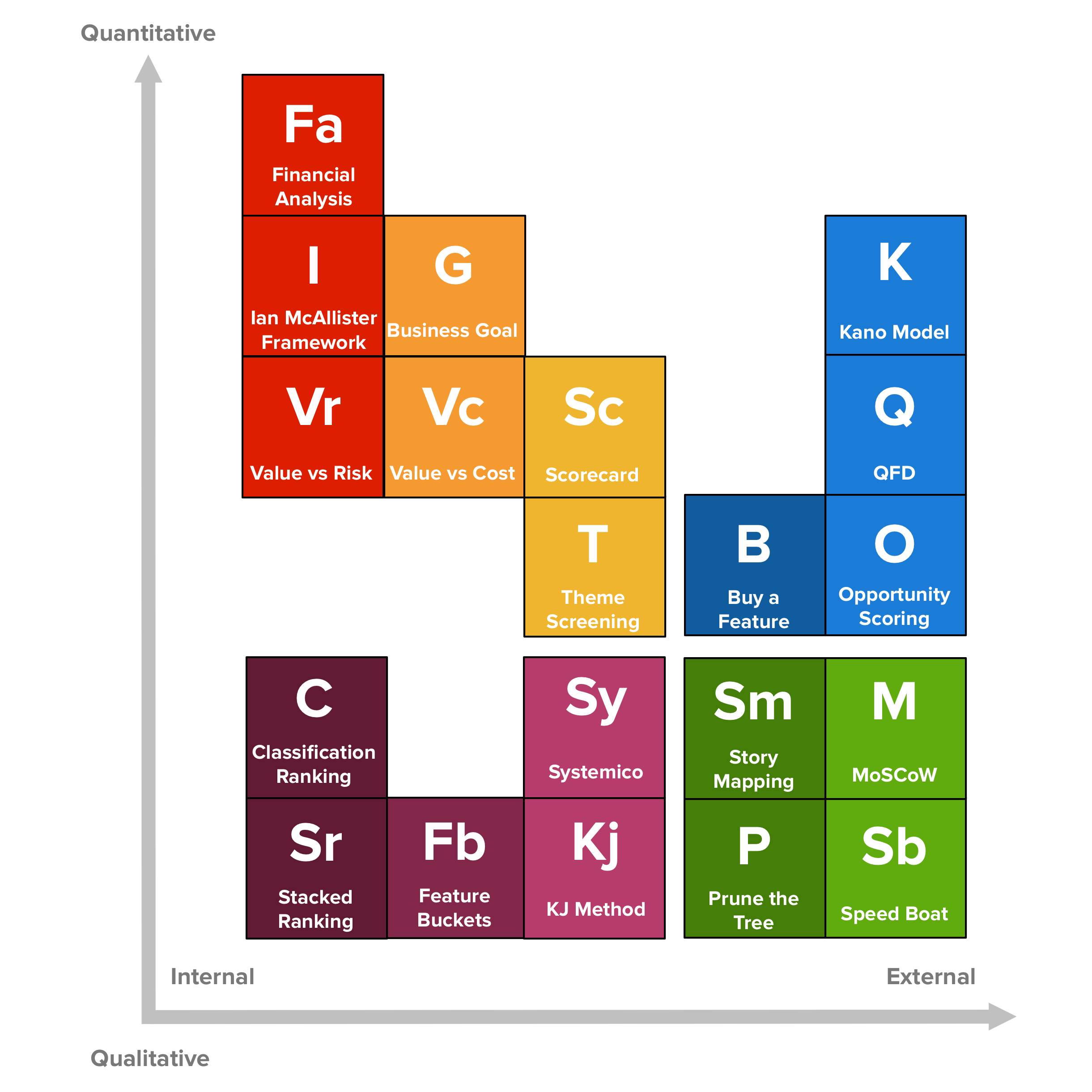
Determining the order should follow a process (https://foldingburritos.com/product-prioritization-techniques/ ) that takes into account both the Value (to the customer and the business, the risk being mitigated, or the opportunity being enabled) and the Effort (complexity of the work, time it will take to complete, learning opportunity to facilitate, etc)
The Backlog should contain enough tickets for the team to work on for the next 3-6 iterations, maximum. With the tickets for the current and next iteration being Refined. Our current velocity is c.13 tickets / iteration. Therefore the Backlog should be between 39-78 tickets. It’s currently 863. It needs radical pruning (for duplicate tickets, placeholder tickets, old tickets that we ‘thought we might work on at some point’ but that will actually never get prioritised).
New skeleton tickets to be worked on in the next 3-6 iterations. Also tickets that have been through Refinement (and flagged as Refined). Periodically, the team will take Refined tickets from the top of the Backlog and add them to Ready for Development. These tickets can be both product development tickets, or tech improvement tickets:
- Tech improvement ideas will initially start off in the Tech Improvement spreadsheet (anyone can add to this).
- From the evaluation carried out there, the Trello Roadmap will be added to with the bigger and higher priority work.
- The Roadmap Tech improvement items, when in the Next or Now columns will be duplicated within Jira.
...
Refinement
Which tickets should be refined?
How should we approach estimation?
What sized tickets should we end up with?
What constitutes a shared understanding of the ticket?
When should something be a ticket / Acceptance Criteria / Sub-task?
...
Anything at the top of the Backlog that has not been flagged as Refined is a prime candidate to move to the Refinement column. The Refinement column is also the designated column for any tickets being generated as a result of a LiveDefect - to encourage us to refine and prioritise this ticket to mitigate the LiveDefect recurring. When the number of tickets in Refinement exceeds the WIP limit, as a result of creating some following a LiveDefect, this should trigger an immediate ad-hoc Refinement session (straight after stand up is often a good time for it).
...
While we’re not now formally estimating with Story points, we need to do some degree of estimation in order to decide whether a ticket is too big and needs splitting. Some degree of uncertainty is acceptable in a Refined ticket. But where that uncertainty is too great, create a SPIKE ticket(s) to get sufficient confirmation to proceed. Indicate elements to investigate early in a ticket. Include uncertainty and positivity bias elements when estimating.
...
Focus on small vertical slices (no more mega-tickets). Vertical slicing can be hard to do. It can take some thought and even lateral thinking. Consider this framework for how to vertically slice work, if you can think of nothing obvious.
Agile working with Kanban is about finding a happy balance between tickets that are small enough to move through the steps in the workflow rapidly, but that also encourage (require?) collaboration between team mates with different perspectives.
...
For a ticket to be flagged as Refined, requires it to be detailed enough that anyone in the team could lead on working on the ticket (and would be able to work out who else to collaborate with to complete the ticket). There should be enough detail for someone to determine how to create one or more experiments towards an overall solution.
...
Ready for Development
What does “Ready for Development” look like?
Clear, testable Acceptance Criteria
Appropriately Sub-tasked
Flagged as Refined
Anyone can pick the ticket up and make a start. Essentially, the ticket has been Refined correctly!
It’s a pool of the top priority tickets (that’s actually a subset of the Backlog). But the team focus should always be on the throughput of tickets that have already been started, over bringing new work in
Allow time at the start to enable a TDD approach to development - as a team we have committed to TDD by default.
The Sub-tasks should indicate who should collaborate on the ticket (avoiding siloed working and the greater chance of working off incorrect assumptions that happens when working in that way).
Check that the ticket has been Refined - it should have been flagged, and appear as a yellow ticket with a red flag on it on the Kanban board.
...
Implementing
How will we test this has added value for the customer
Considered for ‘exception’ monitoring
Timely documentation
#Terraformfirst
Avoid scope creep
Leave Slack for #fire-fire
...
As well as TDD as a coding approach, also consider how the ticket will be tested to confirm it is adding value to the customer at the end of development - are the Acceptance Criteria sufficient?
...
Does this work require specific monitoring (and logging).
...
Consider at what point to start, contribute to and complete documentation (might be easier to do some as you go through, rather than as a task at the end of development). You can also consider preparing for Review from the start - e.g. by baselining your starting point in order to more easily demonstrate the value you add by the end.
...
#Terraformlast is hard, and when collaborating on a ticket, will often result in issues before you get round to it.
...
Notify POs / highlight in Stand up when adding >1 Sub-task after Refinement
...
| View file |
|---|
| name | Getting story ready for Refinement.pptx |
|---|
|
Because Kanban focuses on visualising the steps in the workflow, highlighting work in progress and optimising throughput between steps in the workflow, it is important that everyone is clear about two things:
how we define when something is fit to be pulled* from one step in the workflow to the next
*Kanban is a PULL model, whereas Scrum is a PUSH model. This means tickets should only transition between steps in the workflow at the point that team members start working on them in the new step, not pushed to the next step in the workflow when a team member has finished with them in the previous step. eg. a ticket is moved from PR to Verifying in Stage when a team member has approved and merged the PR and the verifier starts Verifying in Stage;
how we respond as a team to common day-to-day scenarios.
We have started to develop out our Decision Log area, to capture decisions taken that otherwise wouldn’t get documented and might force us into revisiting the decision again (waste of time).
There are also habits that we need to adopt. Some of these are listed in the Ways of Working page. Another example would be to use Stand up to highlight where any work is being blocked / by who / what needs to happen to unblock it.
In Kanban, the tool for achieving this is to define ‘policies’ as reference points for both the above. These are designed to be organic (like the Definition of Done that we’re already familiar with).
Following the team workshop around these policies, I’ve set them out here as a draft for you all to review, comment on/modify.
Policy | Description |
|---|
BacklogWhat is the Backlog? Who populates the Backlog? Should the Backlog be ordered? What should be the size of the Backlog? What goes into the Backlog?
| A record of conversations (ideally a 3 amigos ones) about things to be worked on in the next 3-6 iterations. Anyone, as a result of having the conversation. Remember a Jira ticket is the result of the 3 Cs process - card, conversation, confirmation Everything should be ordered - product-development and tech improvement tickets. As a team we need to align these two sides of the backlog wherever possible (Refinement meetings, Planning ones and Stand ups - up to 30% of what we work on in any iteration should be Tech Improvement).
Determining the order should follow a process (https://foldingburritos.com/product-prioritization-techniques/ ) that takes into account both the Value (to the customer and the business, the risk being mitigated, or the opportunity being enabled) and the Effort (complexity of the work, time it will take to complete, learning opportunity to facilitate, etc) The Backlog should contain enough tickets for the team to work on for the next 3-6 iterations, maximum. With the tickets for the current and next iteration being Refined. Our current velocity is c.13 tickets / iteration. Therefore the Backlog should be between 39-78 tickets. It’s currently 863. It needs radical pruning (for duplicate tickets, placeholder tickets, old tickets that we ‘thought we might work on at some point’ but that will actually never get prioritised). New skeleton tickets to be worked on in the next 3-6 iterations. Also tickets that have been through Refinement (and flagged as Refined). Periodically, the team will take Refined tickets from the top of the Backlog and add them to Ready for Development. These tickets can be both product development tickets, or tech improvement tickets:
- Tech improvement ideas will initially start off in the Tech Improvement spreadsheet (anyone can add to this).
- From the evaluation carried out there, the Trello Roadmap will be added to with the bigger and higher priority work.
- The Roadmap Tech improvement items, when in the Next or Now columns will be duplicated within Jira.
|
RefinementWhich tickets should be refined? How should we approach estimation? What sized tickets should we end up with? What constitutes a shared understanding of the ticket? When should something be a ticket / Acceptance Criteria / Sub-task? What’s the Definition of Done?
| Anything at the top of the Backlog that has not been flagged as Refined is a prime candidate to move to the Refinement column. The Refinement column is also the designated column for any tickets being generated as a result of a LiveDefect - to encourage us to refine and prioritise this ticket to mitigate the LiveDefect recurring. When the number of tickets in Refinement exceeds the WIP limit, as a result of creating some following a LiveDefect, this should trigger an immediate ad-hoc Refinement session (straight after stand up is often a good time for it). Refinement is also the default column for newly created Retro Actions. We have now moved to trial basic estimating of tickets across Product Teams in order to help us to determine the order we should work on tickets (green combinations through to red combinations of the below). We have agreed to do the following: Estimate Value using High | Medium | Low(note when estimating value, take into account especially any input from users and stakeholders - it may not always be easy for the Product Team alone to assess value); and Estimate Effort using Small | Medium | Large (note when we talk about effort, we’re implying complexity, NOT time. Not time, because we do not yet know who is going to do the work, neither do we yet know whether one person or more than one person will be doing the work - so time is a completely unknown quantity. Effort/complexity estimation is designed to surface different levels of understanding of a ticket such that the team can have a discussion around that effort/complexity. In doing so, any member of the team should have enough comprehension to pick the ticket up - also refer to the /wiki/spaces/NTCS/pages/1264091146 page to see who the experts are in any area of our work, if further information/pairing/clarification is needed)
Some degree of uncertainty is acceptable in a Refined ticket. But where that uncertainty is too great, create a SPIKE ticket(s) to get sufficient confirmation to proceed. Indicate elements to investigate early in a ticket. Include uncertainty and positivity bias elements when estimating.
Focus on small vertical slices (no more mega-tickets). Vertical slicing can be hard to do. It can take some thought and even lateral thinking. Consider this framework for how to vertically slice work, if you can think of nothing obvious.
Agile working with Kanban is about finding a happy balance between tickets that are small enough to move through the steps in the workflow rapidly, but that also encourage (require?) collaboration between team mates with different perspectives. For a ticket to be flagged as Refined, requires it to be detailed enough that anyone in the team could lead on working on the ticket (and would be able to work out who else to collaborate with to complete the ticket). There should be enough detail for someone to determine how to create one or more experiments towards an overall solution. A ticket needs to meet INVESTcriteria.
Acceptance Criteria should be a list of statements that can be turned into tests to determine whether the ticket is complete. The Gherkin format that is very popular in this BDD approach and is explained with examples in this article.
Sub-tasks should focus on how to split the ticket into pieces that enable collaboration.
”Good stories involve multiple people. Each subtask usually only involves one person.” Definitions of Done are confirmed - these depend on the type of ticket. DoDs are listed on this page. For Retro actions, specific DoDs need to be stated. We have also agreed to determine DoDs for non-coding work.
|
Ready for DevelopmentWhat does “Ready for Development” look like? Clear, testable Acceptance Criteria Appropriately Sub-tasked Flagged as Refined
| Anyone can pick the ticket up and make a start. Essentially, the ticket has been Refined correctly!
It’s a pool of the top priority tickets (that’s actually a subset of the Backlog). But the team focus should always be on the throughput of tickets that have already been started, over bringing new work in. Ready for Development should also include Retro actions from the immediate last Retro. These Retro actions must have an owner (not necessarily the only person working on the Retro action, but the person leading / coordinating). The Retro action also needs to have a DoD so we can better ensure that the Retro action can get completed in the coming Iteration. Any Retro action that fails to be worked on in the coming iteration is ice-boxed. This is because we don’t want to fill up the backlog with longed for improvements that we don’t then prioritise, and if it’s important enough, it will resurface in a future Retro session. Allow time at the start to enable a TDD approach to development - as a team we have committed to TDD by default. The Sub-tasks should indicate who should collaborate on the ticket (avoiding siloed working and the greater chance of working off incorrect assumptions that happens when working in that way). Check that the ticket has been Refined - it should have been flagged, and appear as a yellow ticket with a red flag on it on the Kanban board.
|
ImplementingHow will we test this has added value for the customer Considered for ‘exception’ monitoring Timely documentation #Terraformfirst Avoid scope creep Leave space for #fire-fire Leave space for Support tickets
| As well as TDD as a coding approach, also consider how the ticket will be tested to confirm it is adding value to the customer at the end of development - are the Acceptance Criteria sufficient? Does this work require specific monitoring (and logging). Consider at what point to start, contribute to and complete documentation (might be easier to do some as you go through, rather than as a task at the end of development). You can also consider preparing for Review from the start - e.g. by baselining your starting point in order to more easily demonstrate the value you add by the end. #Terraformlast is hard, and when collaborating on a ticket, will often result in issues before you get round to it. Notify PMs / highlight in Stand up when adding >1 Sub-task after Refinement
Sometimes we will discover a ticket is more complex than initially anticipated, once we start working on it. This is often something that happens when we discover some tech debt that we need to ‘boy-scout’ (tidy up while working on a ticket in the same part of the codebase). In order to ensure this doesn’t block a column on the Kanban board please: Bring it up at the next available stand up, or ad-hoc during the day if it’s critical; Further refine and break down the chucky tickets and eventually find a way to tackle them; Where there is more tech debt to tidy up than can comfortably be done with boy-scouting, we have agreed that we should ticket this up as separate work. If that work is small enough and high enough value, move it immediately to Refinement and then Ready for Development - rather than risk it going into the backlog which risks it being forgotten; The final scenario is tech debt that we’re not sure about. This is no different than product development we’re not sure about. This type of work should go in the Ideas log (rather than overfilling our backlog, which we’re trying to keep as lean as possible - 2-3 iterations worth of work).
According to Joseph (Pepe) Kelly, and the team agreed when discussed, we should see a “full” column as undesirable: not only is it a bottleneck that leads to idle workstations/wastage through inefficiency but means that we are unable to respond effectively to a changing environment. If we have a #fire-fire, we should have the capacity to “Implement” a fix without breaking our WIP limits. This column should also be used for Support tickets (e.g. TSS Trainee support tickets). On creation, such tickets should be treated as LiveDefects - placed in Implementing and responded to. Often that response will be to send the Trainee an email and await a response. In this scenario, move the Support ticket back into Ready for Development while awaiting a response from the Trainee. If we are able to help the Trainee without any further information, concentrate on progressing the Support ticket from Implementing and through the workflow to Done.
|
Peer ReviewClear breakdown of what’s been done and why If you merge it, you own it too (who checks the pipeline?) Do not amend and force push after comments have been added Use the PR as a record of discussions Respect the reviewers Check the ACs Number of PRs in flight simultaneously
| Often useful to restate the problem, and describe the solution developed. Tickets should normally be written in a way that ensures collaboration, so as a team we need to appreciate everyone involved in contributing to the ticket ‘owns’ that code. By default, anyone approving a PR should therefore merge the code. Recent developments enable flagging a PR for auto-merging on approval, which is an option to consider vs using the approach of creating a draft PR. Comments are left as a proxy for a two-way respectful and constructive conversation. e.g. give alternative opinions, check for coding standards, spot potential problems, check for boy scouting tidy ups, consider performance issues with the code, etc. The ninth Agile principle is "Continuous attention to technical excellence and good design enhances agility".
Respond with gratitude for the comment and act on it, or justify the approach you have taken. And request confirmation, review and merging. Discussions on a ticket often happen on a Slack chat or a Slack/Teams call. Make sure all discussions outside Git are included, linked, summarised on the PR, for a full version history. Reviewing code shouldn’t be regarded as a tick-box exercise. You should be encouraging reviewers to properly review the code, not just ‘sign it off’ with a “Looks good to me”. Be aware that when you have to submit a PR of >500 lines, you are asking a colleague for a potentially significant investment of time/effort. Use PR to check the ACs. This is the easiest way to work out whether the code is good enough. Strict WIP limit on this step to avoid conflicts.
|
Verifying on StageCheck all amended services are up and working All E2E tests passed Independent verification Manual check
| Use Prometheus by way of systematic review that the services touched on by the PR are all up and working Don’t ignore E2E test errors Early in the Implementation step, ask a colleague to be ready to do the verification - so they are already aware of the work ahead of time Log into the Stage app and manually check the changes have worked as anticipated and not broken anything obvious
|
Verifying on ProdAdd ahow to for testing Review customer value added Independent verification Manual check
| Where testing the new code is not obvious, help out the verifier by adding a how to(e.g. need to push specific job into Lambda, attach test materials, etc) Final opportunity to recheck the value added from the customer perspective (of course, this should have already been considered at Refinement and PR at least, if not all the way through the dev process). At this stage, pay special consideration for how the success of the ticket completed will be measured. As for Verifying on Stage, request a different team member carries out verification on Prod Log into the Prod app and manually check the changes have worked as anticipated and not broken anything obvious - this may be more difficult in the Live environment
|
DocumentingEnsure the affected repo’s READ.ME file(s) are up to date Ensure the Dev handbook is up to date Add to the Review page on Confluence For LiveDefects, fill out an Incident log
| This may have already happened, during Implementation Has anything you’ve done necessitated an update to the Dev handbook and was this done during Implementation, or is it outstanding? Tickets by default will normally be ones where we will want to present our work at Review for feedback. Ensure we’re clear how to walk stakeholders through:
- what’s been done;
- what feedback we’re looking for; and
- any questions we want to ask stakeholders in terms of advising us on next steps As part of the LiveDefect, a skeleton Incident log will usually have been created. Ensure an RCA is carried out as soon after a LiveDefect as possible (multiple perspectives, while everything is still fresh in people’s minds). From this RCA, complete the Incident log.
|
DoneCheck DoD if unsure Check Review page is complete
| See https://hee-tis.atlassian.net/wiki/spaces/NTCS/pages/1286635576/Definition+s+of+Done and 2021-22 Reviews (using the Financial year: Start of April - End of March)
|
{kind=link}